K3s, Freelens y ArgoCD: montando un clúster ligero de principio a fin
Hoy hemos venido a jugar con K3s, una distribución ligera de Kubernetes que cabe en un binario de apenas 70 megas. Este es un articulo ambicioso, que va a ir desde el repo de código hasta el consumo del cluster. Y lo que ocurre es que si montas un Kubernetes "de los grandes" con kubeadm, te das cuenta de que para una prueba en casa o para un entorno de staging modesto, estás usando un cañón para matar moscas. K3s viene a resolver eso: te da las mismas APIs, los mismos manifiestos, el mismo kubectl, pero con un consumo de recursos ridículo y una instalación que dura literalmente lo que tarda en bajar un script de curl.
Y ya que estamos, después de tener el clúster montado vamos a ponerle un par de cosas encima que hacen la vida muchísimo más fácil: Freelens, una interfaz gráfica fork del antiguo Lens que te enseña el clúster de un vistazo, y ArgoCD, que es el pegamento entre tu repositorio Git y el clúster, y que materializa eso del GitOps del que tanto se habla últimamente. Vamos allá.
Antes de meter mano, un poquito de contexto. K3s lo desarrolló Rancher Labs (ahora bajo el paraguas de SUSE) con la idea de tener un Kubernetes pensado para edge computing, IoT, CI/CD y, en general, escenarios donde no tienes 16 cores y 64 gigas para gastar. Las diferencias principales respecto al Kubernetes "vanilla" son:
-
Viene en un solo binario que incluye el control plane, el agent, kubectl, crictl, ctr, etc. Nada de empaquetar 15 cosas separadas.
-
Usa SQLite por defecto en lugar de etcd. Si necesitas alta disponibilidad puedes cambiarlo por etcd embebido o por una base externa (MySQL, Postgres), pero para empezar SQLite te quita un dolor de cabeza.
-
El runtime que trae es containerd directamente, sin Docker por medio. Esto que en su momento fue polémico, hoy es lo habitual también en Kubernetes vanilla desde la 1.24.
-
Trae Traefik como ingress por defecto, CoreDNS, ServiceLB (un load balancer que reemplaza al MetalLB para casos simples) y local-path-provisioner para volúmenes locales. Todo eso ya configurado, sin tener que aplicar manifiestos a mano.
La pega, claro, es que algunas cosas están "ocultas" detrás de la magia de K3s. Si necesitas un control fino y absoluto, posiblemente quieras irte a kubeadm. Pero para el 90% de los casos, K3s sobra.
Preparando las máquinas
Para este artículo voy a usar tres maquinas, una fisica y dos máquinas virtuales corriendo Ubuntu Server 22.04 (vale cualquier distro Linux moderna). El reparto es:
-
k3s-master (192.168.1.50) — Hará de control-plane. 8cores 16GB de RAM, 20 GB de disco.
-
k3s-worker1 (192.168.1.51) — Será el nodo worker. 2 vCPU, 4 GB de RAM, 20 GB de disco.
-
k3s-worker2 (192.168.1.52) — Será el nodo worker. 2 vCPU, 4 GB de RAM, 20 GB de disco.
Lo primero, en ambas máquinas asegúrate de tener el sistema actualizado y de que los nombres de host estén bien configurados, porque luego K3s los usará para identificar los nodos:
sudo apt update && sudo apt upgrade -y
sudo hostnamectl set-hostname k3s-master # en el master
sudo hostnamectl set-hostname k3s-worker1 # en la primera
sudo hostnamectl set-hostname k3s-worker2 # en la segundaY muy importante, comprueba que las tres máquinas se ven entre ellas. Un ping rápido entre ambas y listo. Si tienes firewall activado, abre al menos el puerto 6443 (API de Kubernetes) y el 8472/UDP (Flannel VXLAN, que es la red por defecto de K3s):
sudo ufw allow 6443/tcp
sudo ufw allow 8472/udpInstalando el control-plane
Pues bien, vamos al lío. En la máquina k3s-master lanzamos el script oficial:
curl -sfL https://get.k3s.io | sh -Y eso es todo. En serio. En menos de un minuto tendremos K3s corriendo como un servicio de systemd. Para comprobarlo:
sudo systemctl status k3s
Deberíamos ver algo así:
k3s.service - Lightweight Kubernetes
Loaded: loaded (/etc/systemd/system/k3s.service; enabled; vendor preset: enabled)
Active: active (running) since Sun 2026-06-07 11:14:32 UTC; 47s ago
Docs: https://k3s.io
Main PID: 14782 (k3s-server)
Tasks: 78
Memory: 412.5M
CPU: 18.234sYa tenemos kubectl disponible (viene incluido en el binario de K3s) y podemos consultar los nodos del cluster:
sudo kubectl get nodes
NAME STATUS ROLES AGE VERSION
k3s-master Ready control-plane,master 1m v1.31.4+k3s1Perfecto. Para ahorrarnos teclear sudo cada vez que queramos usar kubectl, copiamos el kubeconfig a nuestro usuario:
mkdir -p ~/.kube
sudo cp /etc/rancher/k3s/k3s.yaml ~/.kube/config
sudo chown $(id -u):$(id -g) ~/.kube/configY ya podemos lanzar kubectl get nodes directamente. Antes de seguir, hay una cosa más que necesitamos para unir el worker: el token de unión. K3s lo genera automáticamente al instalar el server y lo deja aquí:
sudo cat /var/lib/rancher/k3s/server/node-tokenApunta ese token, que es como sale en pantalla, algo del estilo K10abc123...::server:xyz789.... Lo vamos a necesitar enseguida.
Ahora vamos a unir los workers. Para el ejemplo realmente estoy usando dos máquinas virtuales en mi Proxmox. Ahi se pueden ver los dos workers:
Ahora nos vamos a la máquina k3s-worker1 y k3s-worker2 y lanzamos el mismo script de instalación pero con un par de variables de entorno que le dicen "no seas un master, únete a aquel master":
curl -sfL https://get.k3s.io | K3S_URL=https://192.168.1.XX:6443 K3S_TOKEN=K10abc123...::server:xyz789... sh -Sustituye la IP por la de tu master y el token por el que copiaste antes. Cuando termine (otra vez, unos pocos segundos), volvemos al master y consultamos los nodos:
kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k3s-master Ready control-plane 3d1h v1.35.5+k3s1 192.168.1.XX <none> Ubuntu 24.04.4 LTS 6.8.0-124-generic containerd://2.2.3-k3s1
k3s-worker1 Ready <none> 3d22h v1.35.5+k3s1 192.168.1.YY <none> Ubuntu 24.04.4 LTS 6.8.0-107-generic containerd://2.2.3-k3s1
k3s-worker2 Ready <none> 9m30s v1.35.5+k3s1 192.168.1.ZZ <none> Ubuntu 24.04.4 LTS 6.8.0-124-generic containerd://2.2.3-k3s1Ahí lo tenemos. tres nodos, uno haciendo de control-plane y dos workers, conectados y listos para recibir cargas. Si te fijas, el worker tiene ROLES: <none>, lo cual es feo y nos puede dar la sensación de que algo va mal. No es así, simplemente K3s no le pone label de role automáticamente. Si te pica el orgullo estético, le aplicas la label tú mismo:
kubectl label node k3s-worker1 node-role.kubernetes.io/worker=worker
Y ya aparece bonito.
daniel@k3s-worker1:/etc/rancher/k3s$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k3s-master Ready control-plane 3d2h v1.35.5+k3s1 192.168.1.141 <none> Ubuntu 24.04.4 LTS 6.8.0-124-generic containerd://2.2.3-k3s1
k3s-worker1 Ready worker 3d23h v1.35.5+k3s1 192.168.1.13 <none> Ubuntu 24.04.4 LTS 6.8.0-107-generic containerd://2.2.3-k3s1
k3s-worker2 Ready worker 87m v1.35.5+k3s1 192.168.1.65 <none> Ubuntu 24.04.4 LTS 6.8.0-124-generic containerd://2.2.3-k3s1
Vale, ya tenemos el clúster funcionando, pero estar todo el rato con kubectl en la terminal puede ser un poco árido, sobre todo cuando quieres ver muchas cosas a la vez. Aquí es donde entra Freelens, que es un fork comunitario y open source del antiguo Lens (Lens cambió su licencia a un modelo comercial y la comunidad bifurcó el proyecto manteniéndolo libre). Es una aplicación de escritorio multiplataforma, hecha en Electron, que te conecta a cualquier clúster que tengas en tu kubeconfig y te lo enseña todo gráficamente.
Para instalarlo, te vas a su página oficial y descargas el paquete para tu sistema. En Ubuntu yo me he ido a por el .deb:
wget https://github.com/freelensapp/freelens/releases/latest/download/Freelens-amd64.deb
sudo dpkg -i Freelens-amd64.debEn Windows hay instalador .exe y en macOS un .dmg. Para que Freelens vea nuestro clúster, lo más fácil es copiarse el kubeconfig del master a la máquina desde donde vas a usar Freelens:
scp usuario@192.168.1.50:~/.kube/config ~/.kube/configY editar ese fichero para que la IP del server apunte a la IP real del master (por defecto K3s pone 127.0.0.1, que evidentemente no nos vale si lo estamos usando desde otra máquina):
server: https://192.168.1.XX:6443Al abrir Freelens, te aparece la lista de clústeres que ha detectado en tu kubeconfig. Le das clic al de K3s y entras. La interfaz tiene un menú lateral con todo lo que hay en Kubernetes ordenado por categoría: Workloads, Network, Storage, Config, Helm, Custom Resources, etc.
A continuación te dejo una representación del aspecto que tiene la pantalla de Pods una vez te metes en ella. Cada fila es un pod, con su namespace, su estado, el nodo donde corre y los iconos de acciones rápidas (logs, shell, edit YAML):
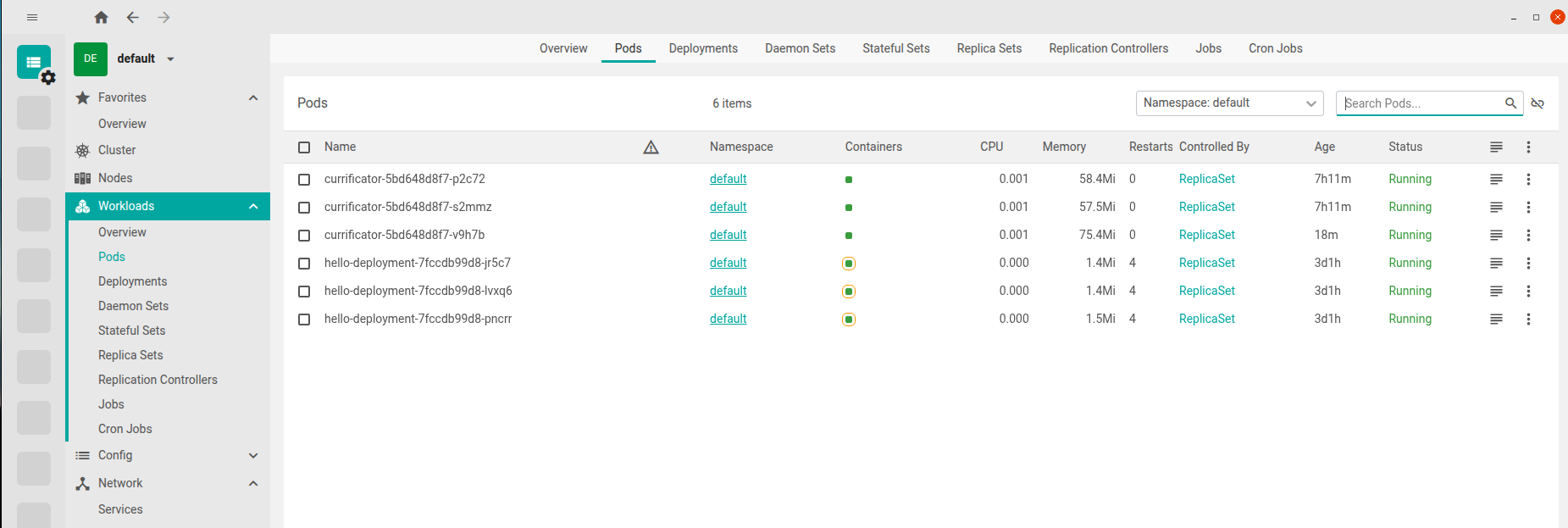
Lo bonito es lo bien que está integrado. Si haces clic en un pod, te abre un panel lateral con todos los detalles: contenedores, eventos, condiciones, métricas básicas (si tienes metrics-server). Si pulsas el botón de "logs" te abre los logs en tiempo real sin tener que escribir kubectl logs -f y, sobre todo, si tienes varios pods de un deployment puedes ver los logs combinados de todos a la vez, cosa que con kubectl es mas pesado.
Una vista interesantre es la que se puede ver en Deployments, que te muestra de un vistazo el estado del rolling update. Un rolling update es una “actualización progresiva”, donde los pods se reemplazan de uno en uno (o de pocos en pocos), de forma que siempre hay al menos unos cuantos pods de la versión vieja respondiendo mientras los nuevos arrancan.
La app no deja de funcionar durante el despliegue.Es lo opuesto a la actualización "de toda la vida" en un servidor tradicional: parar el servicio, sustituir el código, levantar el servicio. Ahí tienes downtime sí o sí, aunque sean 30 segundos. Con rolling update, downtime cero:

Aquí ves cuántas réplicas están disponibles, cuántas no, la imagen que está corriendo, la estrategia de actualización, y con un clic accedes a sus pods asociados. Si haces "edit" puedes modificar el YAML en caliente, y si pulsas el botón de "scale" te aparece un slider para cambiar el número de réplicas sin teclear nada. Para hacer demos o para investigar problemas en producción, te ahorra una barbaridad de tiempo.
Otra cosa muy práctica son las shells integradas: pulsas el icono de terminal en un pod y se te abre una shell embebida dentro de Freelens. Equivalente a kubectl exec -it, pero sin tener que estar copiando nombres de pods. Otra cosa muy interesante es poder hacer un port forward directamente desde un pod para poder entrar en un pod en concreto.
Seleccionamos un pod y en el menu lateral buscamos el boton Port Forward.
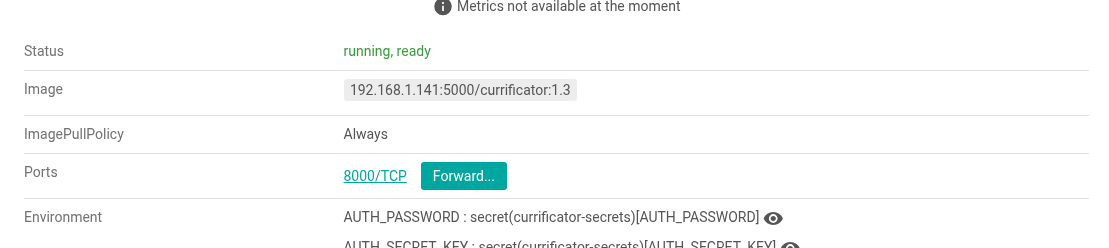 Nos va a pedir un puerto, le dejamos en aleatorio y entramos directamente a su url, en este caso a puesto el puerto 41905:
Nos va a pedir un puerto, le dejamos en aleatorio y entramos directamente a su url, en este caso a puesto el puerto 41905:
y ahora, pasamos al plato fuerte. Hasta ahora, cuando queríamos cambiar algo en el clúster, lo hacíamos a mano: editar el YAML, kubectl apply. Eso funciona, pero tiene tres problemas gordos. Uno, no hay trazabilidad: si alguien hace kubectl edit en producción, no queda registro en ningún sitio salvo en la auditoría de la API (si la tienes activada). Dos, drift: si cambias algo a mano y luego alguien aplica el YAML original sin saberlo, machaca tu cambio. Y tres, no es repetible: si se te muere el clúster, recuperar el estado exacto en el que estaba es un infierno.
GitOps resuelve esto con una idea muy simple: el repositorio Git es la única fuente de verdad. Todo lo que se despliega en el clúster está descrito como código en Git. Nada de kubectl apply manual. Un agente que corre dentro del clúster (ArgoCD) lee el repo, compara con lo que hay desplegado, y si hay diferencias, las aplica. Tienes auditoría gratis (git log), rollback trivial (git revert), y el clúster se vuelve básicamente desechable.
ArgoCD se instala como cualquier otra cosa en Kubernetes, con un manifiesto. Lo metemos en su propio namespace:
kubectl create namespace argocd
kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yamlEl manifiesto despliega un puñado de pods: el argocd-server (la API y la web UI), argocd-repo-server (el que clona los repos), argocd-application-controller (el que vigila las aplicaciones), argocd-redis (caché) y un Dex para autenticación opcional. Esperamos a que estén todos listos:
kubectl get pods -n argocd -wCuando los veas todos en Running, podemos acceder a la UI. Por defecto el servicio es ClusterIP, así que para verlo desde fuera lo más rápido es un port-forward:
kubectl port-forward -n argocd svc/argocd-server 8080:443Y nos vamos a https://localhost:8080 con el navegador. La contraseña inicial del admin la genera él solo y la guarda en un secret:
kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -dLogin con admin y esa contraseña, y dentro.
Conectando un repositorio Git
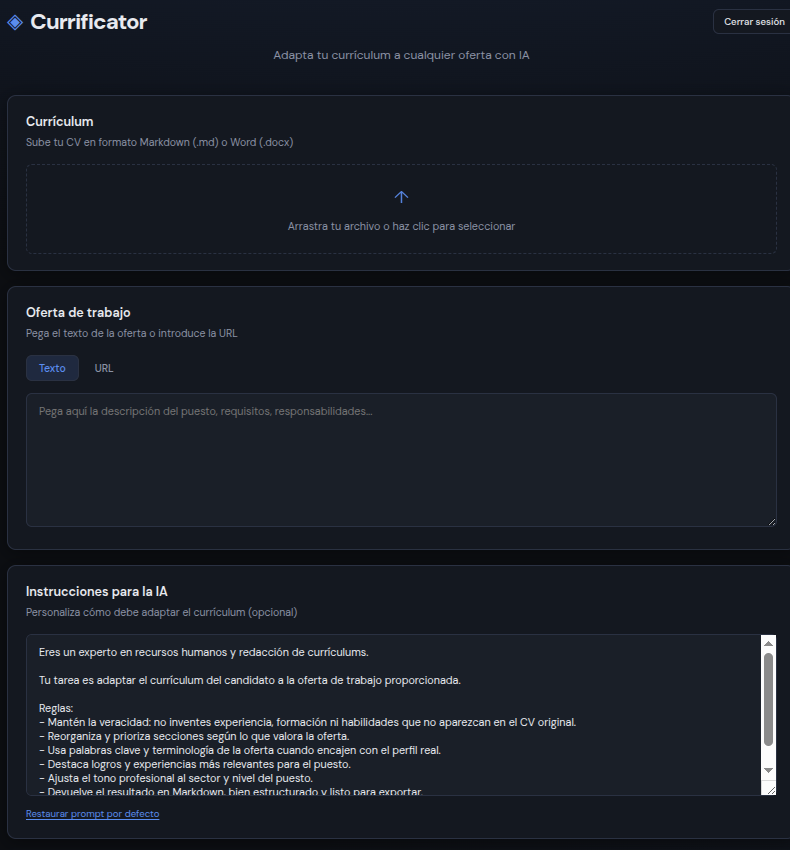
Pues vamos a darle algo que vigilar. Vamos a usar un repo mio de ejemplo (puedes hacerte uno tuyo en GitHub con los manifiestos que quieras). Yo voy a crear una Application de ArgoCD que apunte al repo de uno de mis inventos, El CURRIFICATOR, que es un cacharro que te adapta curriculums a una oferta de trabajo determinada, automáticamente, en base a un prompt que puedes editar en plan, “contesta en inglés” o “añade tal cosa”, y le voy a decir que despliegue en el namespace default. Lo podemos hacer desde la UI con un wizard o por YAML, que es lo elegante:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: currificator
namespace: argocd
spec:
project: default
source:
repoURL: ssh://user@XXX.YYYYYYY.ZZZ:8888/var/repo/currificator.git
targetRevision: HEAD
path: manifiest
destination:
server: https://kubernetes.default.svc
namespace: default
syncPolicy:
automated:
prune: true
selfHeal: trueEsto es lo más importante del artículo, así que detente un segundo a leer ese YAML. Le estamos diciendo a ArgoCD:
-
source: dónde vive la verdad. Un repo de git "in-house", pero podria ser de cualquier parte, en la rama HEAD (último commit), dentro del directorio currificator.
-
destination: dónde aplicar los manifiestos. En este mismo clúster (https://kubernetes.default.svc es la URL interna del API server), en el namespace default.
-
syncPolicy.automated: y aquí está la magia. Con prune: true, si borras un fichero del repo, ArgoCD borra ese recurso del clúster. Con selfHeal: true, si alguien hace kubectl edit a mano y modifica un deployment, ArgoCD detecta el drift y vuelve a aplicar lo que dice el repo. Es decir, el repo gana siempre.
-
Path: Aqui es donde pomenos la ubicacion de nuestros manifiestos en el repo,
Lo aplicamos:
kubectl apply -f application.yamlHasta qui ya hemos visto el manifesto de la aplicación, existen diversos manifiestos que voy a detallar sin profundizar mucho:
el namespace que va a englobar nuestra aplicaciones
apiVersion: v1
kind: Namespace
metadata:
name: miapp
el deployment, la piedra angular del Kubernetes, corre tu contenedor, lo mantiene vivo y replicado:
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: currificator
labels:
app: currificator
spec:
replicas: 3
selector:
matchLabels:
app: currificator
template:
metadata:
labels:
app: currificator
spec:
imagePullSecrets:
- name: registry-credentials
containers:
- name: currificator
image: 192.168.xxx.xxx:5000/currificator:1.4
imagePullPolicy: Always
envFrom:
- secretRef:
name: currificator-secrets
ports:
- containerPort: 8000
El servicio da un punto de acceso a nuestros pods en el cluster desde fuera:
# service.yaml
apiVersion: v1
kind: Service
metadata:
name: currificator
spec:
selector:
app: currificator
ports:
- port: 80
targetPort: 8000
type: ClusterIP # Cambia a LoadBalancer o NodePort si quieres acceso externo
y por ultimo el ingress, que permite a traefix enrutar el trafico desde un dominio al servicio:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: currificator
spec:
rules:
- host: currificator.local
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: currificator
port:
number: 80
Para no hacer demasiado largo este artículo he dejado algunas cosas fuera, como la creacion de un Registry que permite disponer de un repositorio de imágenes, que necesitará el deployment para saber de donde tendrá que obtener las imágenes. Solo comentar que como es self-hosted y no lleva https pues nadie confía en el. Me habría sido más fácil ponerlo en Github Container Registry o Docker hub. Dejaré aquí al menos la conf para lanzar la instalacion de lo que he usado para arrancar el docker registry:
docker run -d
--name registry
--restart=always
-p 5000:5000
-v /opt/registry-data:/var/lib/registry
-v /opt/registry-auth:/auth
-e REGISTRY_AUTH=htpasswd
-e REGISTRY_AUTH_HTPASSWD_REALM="Registry Realm"
-e REGISTRY_AUTH_HTPASSWD_PATH=/auth/htpasswd
-e REGISTRY_STORAGE_DELETE_ENABLED=true
-e "REGISTRY_HTTP_HEADERS_Access-Control-Allow-Origin=[http://localhost:8080]"
-e "REGISTRY_HTTP_HEADERS_Access-Control-Allow-Methods=[HEAD,GET,OPTIONS,DELETE]"
-e "REGISTRY_HTTP_HEADERS_Access-Control-Allow-Credentials=[true]"
-e "REGISTRY_HTTP_HEADERS_Access-Control-Allow-Headers=[Authorization,Accept,Cache-Control]"
-e "REGISTRY_HTTP_HEADERS_Access-Control-Expose-Headers=[Docker-Content-Digest]"
registry:3
Hay que tener en cuenta que ArgoCD no va a vigilar el código de la aplicación, va a revisar única exclusivamente los manifiestos, y por mucho que haya tags nuevos de imágenes nuevas en el registry si el manifiesto no lo indica no se desplegarán. Por otro lado, ArgoCD también vigila el clúster. Tiene un watch contra la API de Kubernetes, así que en cuanto un recurso gestionado por una Application cambie (sea porque kubectl, sea porque un controller, sea porque alguien tocó algo a mano), se entera y compara. Si está en modo selfHeal: true, lo revierte. Si no, simplemente te lo marca como OutOfSync en la UI y te deja decidir.
Es mandatorio, habilitar a argo el acceso al repositorio del codigo, para ello sera preciso añadir el certificado del host donde estan los repos de git. Una de las tecnicas es añadir los certificados del repo a argo, aunque se podria hacer tambien gestionandolo declarativamente con un configmap.
Tomo el certificado de mi repo y listo:
# Una sola vez: confiar en el host SSH
ssh-keyscan -p port xxx.yyyyy.zzz | argocd cert add-ssh --batch
# Ya tantas veces como quieras: añadir repos
argocd repo add ssh://user@xxx.yyyyy.zzz:port/var/repo/currificator.git --ssh-private-key-path ~/.ssh/id_ed25519
y responderá con:
Repository 'ssh://user@xxx.yyyyyy.zzz:port/var/repo/currificator.git' added
comprobamos con:
argocd repo list
Otro capitulo importante es el de las variables de entorno. Mi código no sabe nada de Kubernetes, ni de secrets ni sealed secrets. Pongamos que el codigo necesita un apikey que usa para hablar con la IA y construir los curriculums. En algun punto del codigo hay un:
api_key = os.environ["OPENAI_API_KEY"]
En mi local habrá un secrets.yaml, donde estarán escritas mis variables de entorno, y seguirán para siempre en local, nunca jamas en el git. Y lanzamos el siguiente comando
kubectl create secret generic currificator-secrets
--from-literal=OPENAI_API_KEY=sk-proj-abc123real...
--dry-run=client -o yaml > secret.yaml
Esto genera mi secrets.yaml, y estarán las variables en base64.
Perfecto, a continuación creamos el sealed secrets. Y lo haremos con:
kubeseal -o yaml < secret.yaml > sealedsecret.yaml
Este kubeseal que habrá que instalar previamente con un:
KUBESEAL_VERSION='0.27.1'
wget "https://github.com/bitnami-labs/sealed-secrets/releases/download/v${KUBESEAL_VERSION}/kubeseal-${KUBESEAL_VERSION}-linux-amd64.tar.gz"
tar -xzf kubeseal-${KUBESEAL_VERSION}-linux-amd64.tar.gz kubeseal
sudo install -m 755 kubeseal /usr/local/bin/kubesealSe va a conectar con el controller de nuestro cluster y le va a pedir la clave pública, y con dicha clave, va a codificar el las variables de entorno y generará algo así:
apiVersion: bitnami.com/v1alpha1
kind: SealedSecret
metadata:
name: currificator-secrets
namespace: default
spec:
encryptedData:
OPENAI_API_KEY: AgBxK2Z9pLm7nF4hJqWXyZpAbCdEf...
Este si se va a pushear a git, y llegará al cluster. Cuando eso ocurra el controller de Sealed Secrets, que es un pod corriendo permanentemente en kube-system, verá que hay un SealedSecret nuevo. Lo lee, lo descifra con su clave privada, y creará un Secret normal de Kubernetes con los datos en plano, en el mismo namespace que el SealedSecret:
Es entonces cuando el deployment que ya está al tanto del nombre del secret, abajo del todo en la key envFrom, podrá disponer de los valores:
apiVersion: apps/v1
kind: Deployment
metadata:
name: currificator
spec:
replicas: 2
selector:
matchLabels:
app: currificator
template:
metadata:
labels:
app: currificator
spec:
containers:
- name: currificator
image: xxx.xxx.xxx.xxx:5000/currificator:1.4
ports:
- containerPort: 8000
envFrom:
- secretRef:
name: currificator-secrets # ← este es el Secret normal
Ese envFrom le dice a Kubernetes, oye, ve al currificator secrets y mete las claves del secret como variables de entorno. La app las lee y las usa como si hubieran estado en el repo desde el principio.
Detalle importante el controlador de sealed secrets hay que instalarlo aparte:
kubectl apply -f https://github.com/bitnami-labs/sealed-secrets/releases/download/v0.27.1/controller.yaml
Y de vuelta en la UI verás aparecer la aplicación. A los pocos segundos, ArgoCD habrá clonado el repo, leído los manifiestos y los habrá aplicado. Lo bonito es la vista en árbol que te muestra: la Application → los Deployments → los ReplicaSets → los Pods, todo conectado y con su estado (Healthy/Synced/OutOfSync) en colores. Algo así:
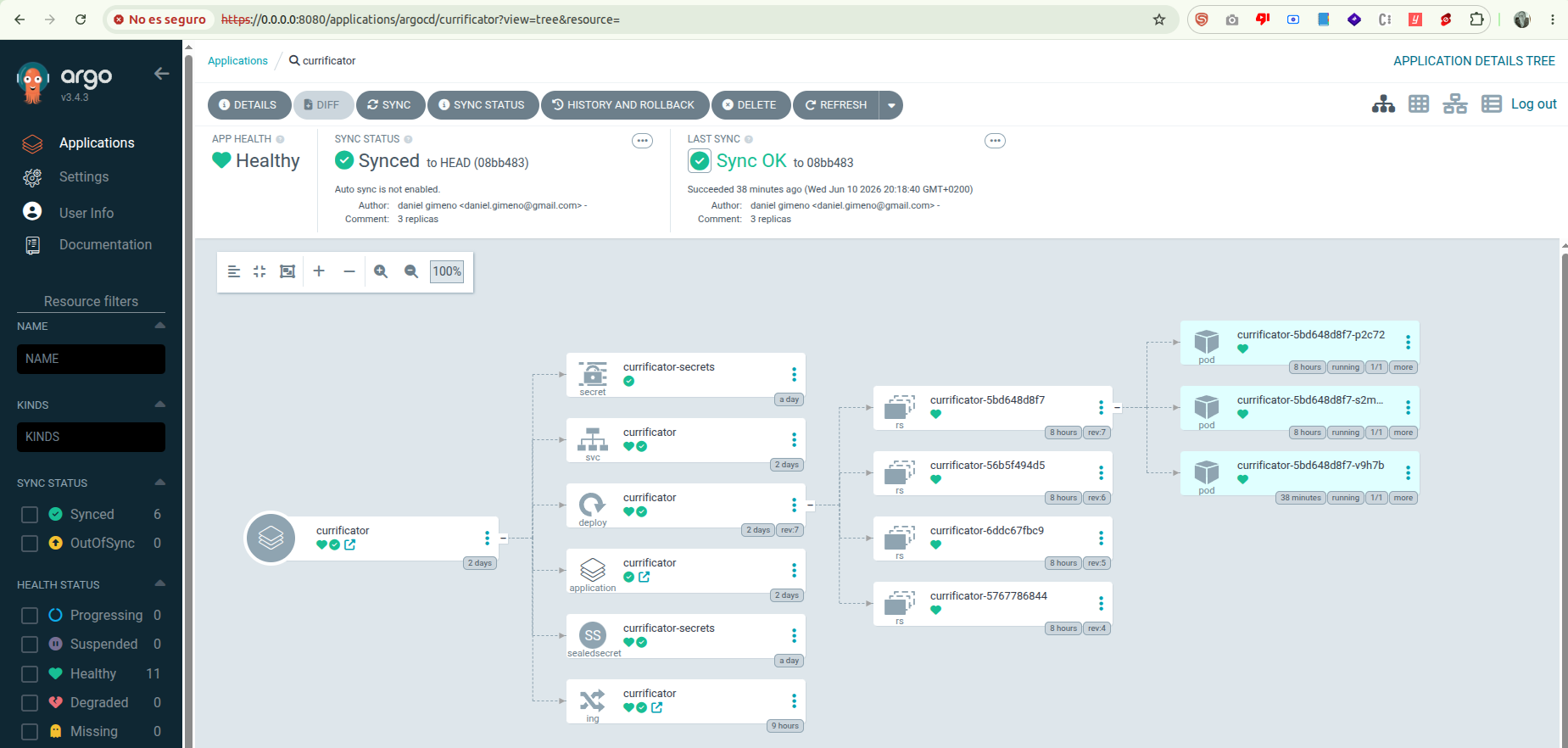
Lo realmente interesante es cómo se entera ArgoCD de los cambios. Tiene dos mecanismos que funcionan a la vez:
Polling periódico del repo Git. Por defecto cada 3 minutos (configurable con timeout.reconciliation en el ConfigMap argocd-cm) hace un git ls-remote al repo para ver si el commit del que tira ha cambiado. Si ha cambiado, clona, calcula el diff con el estado actual del clúster y aplica lo que falte. Esto se llama reconciliation loop y es exactamente el mismo patrón que usa Kubernetes internamente: comparar estado deseado con estado real, y converger.
Webhooks de Git (opcional pero recomendado). Si configuras un webhook en GitHub/GitLab/Bitbucket apuntando a https://argocd.tudominio.com/api/webhook, ArgoCD se entera del push instantáneamente sin esperar al siguiente ciclo de polling. Esto es genial para entornos donde los despliegues tienen que ser rápidos.
Muy bien, vamos a recapitular. Hemos actualizado el codigo y lo normal seria tener todo integraddo en un pipeline de CI: cuando construyes una nueva imagen, el propio pipeline hace push al registry y commit al repo de manifiestos con el nuevo tag. Yo no tengo ningun sitema de CI asi que hice mi push al registro a maneja. ArgoCD lo coge en el siguiente ciclo o por webhook.
La cosa quedaría asi:
1. Tú modificas un manifiesto en tu repo de Git. Por ejemplo cambias replicas: 3 por replicas: 5.
2. Haces git commit && git push.
3. El repo de git dispara el webhook a ArgoCD (o ArgoCD lo detecta en su siguiente polling).
4. ArgoCD clona el repo, ve que el deployment del clúster tiene 3 réplicas y el de Git dice 5. Estado: OutOfSync.
5. Como tienes automated.selfHeal: true, ArgoCD aplica el cambio.
6. Kubernetes escala el deployment a 5 réplicas. Estado: Synced y Healthy.
7. Tú en Freelens ves los dos nuevos pods aparecer en tiempo real, en el nodo worker que tenga capacidad.
Todo el cambio queda trazado en git log. Si quieres revertir, git revert y vuelves al estado anterior automáticamente. Si tu clúster muere y montas uno nuevo, lo único que tienes que hacer es reinstalar K3s, instalar ArgoCD, registrar la Application apuntando al mismo repo, y todo lo que tenías vuelve a su sitio. Eso es lo que la gente quiere decir cuando habla de "infraestructura inmutable" y "clústeres como ganado, no como mascotas".
Vale, el cluster esta funcionando, ahora veamos como se consume. Lanzamos un get servicios:
kubectl get svc
Verás algo así:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.43.0.1 <none> 443/TCP 2d
currificator ClusterIP 10.43.187.42 <none> 80/TCP 5m
La columna CLUSTER-IP es la dirección virtual de nuestro servicio: en este ejemplo 10.43.187.42. Es una IP estable que apunta a lso pods con la label app=currificator. Importante: esta IP solo es accesible desde dentro del cluster, no desde fuera. Si te conectas por SSH a cualquier nodo y haces curl http://10.43.187.42, te responde. Desde tu portátil fuera del cluster, no llegas.
Aquí toca aclarar un punto que confunde al principio. Un Service de tipo ClusterIP (el de por defecto) es perfecto para tráfico interno entre microservicios, pero no para exponer la app al exterior. Para exponerla tienes tres caminos:
-NodePort: abre un puerto en el rango 30000-32767 en todos los nodos. Funcional pero feo de cara al usuario, porque hay que recordar puertos altos.
-LoadBalancer: te da una IP "externa" directamente. En K3s lo resuelve ServiceLB usando las IPs de los nodos. Útil sobre todo para servicios no-HTTP (TCP raw, UDP), donde el Ingress no llega.
-Ingres: para HTTP/HTTPS, que es nuestro caso. El Service se queda como ClusterIP (interno) y delante ponemos un Ingress que enruta por dominio y path hacia el Service. Es el patrón estándar en producción: una sola IP pública sirve para decenas de aplicaciones, cada una con su dominio.
Como Currificator es una app web, vamos a por la opción Ingress, que de paso nos aprovecha el Traefik que K3s ya tiene corriendo. El manifiesto Ingress que vimos antes le dice a Traefik que todo lo que llegue a currificator.local lo reenvíe al Service currificator en el puerto 80.
Es practico este comando para ver cuales son los endpoints que componen el cluster
kubectl describe svc currificator
Warning: v1 Endpoints is deprecated in v1.33+; use discovery.k8s.io/v1 EndpointSlice
Name: currificator
Namespace: default
Labels: <none>
Annotations: argocd.argoproj.io/tracking-id: currificator:/Service:default/currificator
Selector: app=currificator
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.43.164.48
IPs: 10.43.164.48
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 10.42.1.12:80,10.42.2.34:80
Session Affinity: None
Events: <none>
La fila de Endpoints lista las IPs reales de los pods detrás del Service. Si haces un curl a cualquiera de ellas desde dentro del cluster, la app responde directamente. Pero ya no necesitamos hacer eso a mano: cuando entremos por el Ingress, Traefik se encargará de balancear hacia esos pods automáticamente.
Ahora editamos nuestro /etc/hosts en el portátil y le decimos que currificator.local apunta a la IP de cualquier nodo del cluster:
192.168.1.141 currificator.local
Cuando el ingres reciba una peticion del dominio, como si fuera un virtual host de Apache, lo mandará al servicio:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: currificator
spec:
rules:
- host: currificator.local
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: currificator
port:
number: 80
Y ya, por fin, aquí lo tenemos con nosotros:
El currrrrificator:
Espero que os haya sido de utilidad, y que os haya resultado tan interesante como a mi, un saludo y hasta la proxima